
A journey into serverless.
A few months ago, we started work on Moonshot Insurance IT platform. From the outset, we made a deliberate choice to leverage the serverless model and see how far we could go with it.
This article describes how we put this serverless strategy in place, the different iterations we went through, what issues we faced and how we solved them (and what issues remain to be solved!). In other words, I’m going to talk about our process rather than just our current architecture, hence the title 😉.
Why the journey rather than the destination? This is an attempt to fill the void between the countless serverless tutorials (“Write your First Lambda !!!”) and more advanced articles such as Yan Cui’s excellent series Yubl’s road to Serverless (the other inspiration for this article’s title). Hopefully, describing our trials, failures and successes will help others struggling with the same questions.
The main focus in this article is on our APIs, which nicely illustrate the different topics and follow a very common serverless pattern:
- Route 53 and custom domains are used to route the requests;
- API Gateway exposes the API;
- Lambda functions are used for business logic and custom authentication;
- Data storage is handled by DynamoDB.
In the beginning was the console

Our first step was to create the Lambda functions and API gateway manually, through the AWS console. While this is fine to explore the different configuration options and deploy a quick proof of concept, it doesn’t scale. The process is error-prone; packaging and deploying Lambda functions manually is a pain, and configuring API Gateway is needlessly complicated when you’re not familiar with the service. Even if you are, the terminology and arcane interface can still trip you up: I still don’t know off the top of my head the difference between Method Request and Integration Request… And where do you activate logs again? (answer: in the “Stages” sub-menu. Obviously. 🤔)
So, once we understood our initial workflow and were comfortable with the basic architecture, we started looking at ways to automate it.
In comes Apex
We looked at different frameworks and settled on Apex. This framework was a good fit for our initial use case (make changes to a Lambda function, package it and deploy it) while not trying to do too much. Apex also manages environment variables and function settings, aliases, and can be extended via hooks — for instance, to install Python dependencies before the build step.
So with Apex and a few shell scripts we now had a much more robust way to deploy our Lambda functions. We use BitBucket for version control, and BitBucket provides a CI/CD tool called Pipelines. Armed with our new deployment scripts, we could now deploy and test our Lambda functions with each commit (more on tests in a next article).
However, managing API Gateway was still highly manual.

SAM is AWS’s Serverless Application Model
Simply put, it’s a super-set of the CloudFormation syntax which offers convenient shortcuts for the description and deployment of serverless apps. In particular, it can use Swagger files to configure API Gateway; not only the models and resources (although this is already a big win), but also the integration with Lambda functions and custom authenticators.
What this means in practice is that you can take your existing Swagger file, complete it with a few x-amazon-apigateway-* descriptors, and just like that your API is deployed and integrated with your Lambda functions with all the correct models and behaviors. No need to worry ever again about how to use the API console 🎉
Building on SAM, we built a complete CloudFormation template describing our API integration, the Lambda functions, as well as the associated IAM roles, log rules and so on. We now had a way to update our entire stack, and even rebuild it from scratch if the need arose. Infra as code!
It’s also around this time that we finally threw in the towel and isolated our staging and production platforms in dedicated AWS accounts. Previously we had kept them both in the same account, using Lambda aliases and API stages to distinguish them. But it was becoming increasingly complicated to reason about the release cycle, when to change aliases or which stage should point to which version. Security and keeping the contexts isolated was also a big pain. So we followed AWS best practices and set up a separate account for production, as well as giving each developer their own account. It’s not very expensive, since with a serverless architecture you only get billed for actual usage. And now that we could easily set up new environments by running our CloudFormation scripts, we went nuts 😁
Getting containers on board

At this stage we only had one API, living in one repo, with all our deployment scripts and templates tucked away in a /infra directory. Then came the day when we started to work on a second API...
We graduated our CI code to its own repository and created a Docker image containing all the scripts and necessary tooling, while the configuration files stayed in the original repo.
Separating code from configuration allows us to easily replicate the set-up for new APIs. The Docker image provides a consistent environment whether we run the scripts locally, e.g. when testing on dev accounts, or through the CI server.
So, to recap. At this stage, about 3 months into building our platform,we used CloudFormation to deploy and update our API gateway and the associated AWS infrastructure (IAM roles, Lambda functions, etc). We deployed our Lambda functions, including their dependencies and environment variables, using Apex. Apex hooks and custom shell scripts were used to run tests before and after deployment. All these scripts and tools were packaged in a Docker image. All neat and tidy and working well… You’re guessing what comes next, right ? Let’s throw everything away and start again from scratch
Well, we didn’t throw everything away, but we did make a lot of changes.
First, the why. Although we had built a functioning, complete set-up, we had a number of pain points that became obvious with use:
- We used different tooling to manage Lambda functions (Apex) and API Gateway (SAM / CloudFormation). This meant in practice that new versions of the Lambda functions were deployed automatically, but changes in the Swagger file required a manual action to upgrade the API Gateway configuration. Also, it prevented us from having a clean, simple rollback process.
- We had a lot of custom shell scripts around Apex. This was a classic case of feature creep: as we added and automated new steps in the CI process, our scripts gradually became more complex and we eventually ended up with a lot of shell code that we were uncomfortable maintaining in the long run.
- Our CloudFormation file was static, which meant copy-pasting whole sections each time we added a new Lambda function.
Taken separately, we could live with each of these issues. But together, they suggested we should review our tooling choices.
The first step was to replace the shell scripts by Ansible playbooks, giving us a more modular and easier to maintain CI framework. Switching to Ansible also enabled us to use templates rather than static CloudFormation files; one line in the configuration file is now enough to create all the necessary resources for a new Lambda function. Finally, armed with our templating engine and existing playbooks, we extended the CloudFormation files to handle Lambda deployment as well. This allowed us to remove Apex from the stack and manage all our deployment steps through CloudFormation.
Frozen stacks

The more astute readers will have noticed that this latest setup doesn’t address one of the pain points mentioned above: the need for a simple way to roll back. And indeed, while having a single tool and set of playbooks makes it easier to deploy and roll back, it still takes a bit of time to build the CloudFormation package, upload it and run it. Furthermore, the new version can only be tested (in production) after it is live. So if there’s an issue that wasn’t detected in staging, it can potentially break the production platform before we have a chance to identify it.
To get around these issues we moved to an immutable model: every time we deploy, we create a completely new stack with a unique ID. Once the stack is deployed and tested, we divert the traffic to the new version. If we need to roll back, we can switch back to the previous version by simply changing which stack the custom domain name points to.
This setup completely removes the notion of “upgrading” an existing deployment: a stack lifecycle is simply deployment -> activation -> deletion. Deploying a new version means rebuilding the entire environment from scratch — no configuration drift, no manual upgrades to keep track of. If a stack builds and deploys in our staging environment, we’re very confident that it will build and deploy in production — the only possible issues come from objects outside of the stack, such as IAM roles for the CI server or persistent storage (DynamoDB tables and SSM Parameter Store in our case).
Wrap-up
Thanks for making it this far! Here’s a recap of what we learned on our journey (so far) into serverless:
- Infra as code rocks! Use a framework to describe your resources and build/upgrade your infra automatically.
- A single framework/tooling chain is easier to manage than using a collection of tools (duh). We ended up rolling our own framework on top of AWS CloudFormation and Ansible, but do give a look at serverless and Terraform first! (as to why we didn’t use Serverless ourselves, two words: Swagger support).
- Use separate AWS accounts for production and staging.
- Actually, go ahead and create accounts for all your developers as well; infra as code makes it easy, and serverless makes it cheap.
- Immutable infrastructure makes it easy to reason about the state of your stacks and how to upgrade. But it brings its own challenges, such as service discovery.
API architecture
In part 1, I briefly mentioned that our API are built out of stock AWS components, mainly API gateway and Lambda functions. Now’s the time for a closer look.
Here is what a typical API stack looks like:
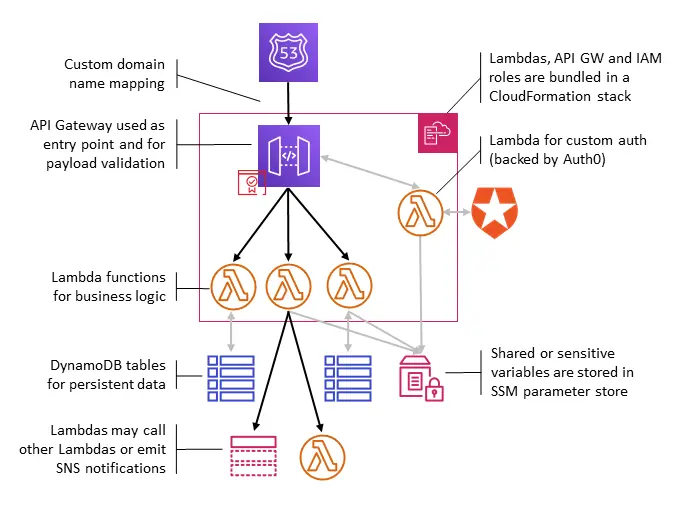
The API gateway and Lambda functions, as well as the supporting IAM roles, are bundled in a CloudFormation stack which is deployed from scratch on each change.
The public URL of the API points to the currently active stack through a custom domain name mapping; in other words, moving to a new version or rolling back is simply changing a pointer to a different stack. Custom domain names can manage several path mappings, allowing us to expose different versions of an API simultaneously (e.g. /v1 and /v2 can point to 2 different stacks).
In addition to this stack, DynamoDB tables are used to store persistent data, and we make heavy use of the SSM parameter store both for sensitive information (e.g. API keys) or shared information (for instance, the ID of the currently active stack). Lambda functions call each other directly or use SNS to publish notifications.
Testing

Testing Lambda functions is complicated. Even more so when they act as glue between services, some of which are provided by third parties. How do you test locally? How do you test once you’ve deployed? Should you mock the services your Lambdas are calling, or call the real thing? What about writing to Dynamo, or posting to SNS?
On this topic, we followed the “different paths, same test” strategy described in this post. During tests we call our Lambda functions in one of two different ways: either locally by calling the code directly, or remotely by calling the Lambda function through the API gateway (or through boto for Lambda functions which do not have a public endpoint). This switch is managed by an environment variable, and some helper code that abstracts the different ways to call a lambda function; the test code however is exactly the same for local and remote tests.
This allows us to write all tests as unit tests; they are run locally before deployment, and remotely, as integration tests, after deployment (but before the stack becomes active).
To mock, or not to mock
We call third-party services rather than mocking them, since a good deal of our code is about integrating with those services — so we want to catch integration issues or changes in the interface as early as possible. This approach works well in development and staging environments. However, calling third-party services in production creates “real” objects and transactions. We roll these transactions back at the end of the tests and/or isolate them on specific test accounts. But we’re still looking for a better way to manage the trade-off between the safety of systematic integration tests and the risk of creating fake transactions in production.
Another ongoing area of improvement is how to stub synchronous calls to other internal services. For integration tests this isn’t really an issue, since we want to make sure the platform as a whole works as expected. However, this makes local/unit tests more complex than they should be whenever a Lambda function calls another API: the called service has to be deployed and running on the developer’s account, and there’s some environment fiddling to get the same behavior as what happens in staging or production. And sometimes tests fail due to incorrect behavior in the called service, which is not always easy to track down in the logs. To resolve these issues, we’ve started to mock internal services so that we can have more isolated unit tests.
Our testing methodology is still a work in progress. The set-up outlined above worked really well when we had small APIs and they were mostly independent. It still holds up well for isolated or loosely coupled services; but as our platform grows and our services become more interconnected, we’re facing new challenges and reviewing how to best handle our unit and integration tests.
Logging

Logging is like chocolate: when it is good, it is very, very good; and when it is bad, it is better than nothing. Yes, this is a shameless reboot of a saying originally about documentation and, well… not chocolate.
Logging is very straightforward in Lambda. You can use the standard logging library, or even just print to stdout, and the logs will end up in AWS’ logging solution Cloudwatch. Unfortunately, Cloudwatch falls in the “better than nothing” category, and comes reeeeally close to the “better off without it” tier. I won’t explain why Cloudwatch is not ideal to explore logs, especially when you have a lot of Lambda functions. If you’ve used it, you know why. And if you haven’t used it… Lucky you, I guess.
Our first approach to more robust log exploration was to deploy an ELK stack. This is very simple to do with the ELK service provided by Amazon. However, this solution had a few issues for us: it’s not managed; you have to add and manage your own authentication if you don’t want the world to read your logs; and it’s ridiculously easy to over-provision — when we tried it, the default template spun up 4 extra-large VMs (in each of our environments), leading to an invoice where our biggest spend was on logging 🤦♂️(leading, in turn, to adding billing alarms to our account).
Enter Datadog
We took a look at different logging/monitoring services and settled on Datadog. Datadog provides monitoring and alerting features which are well integrated with AWS, and since early 2018 has added log management to its features. This allows us to have a comprehensive monitoring dashboard and access to all of our logs in the same place.
We export our logs to Datadog using the standard log forwarding mechanism (a special Lambda function triggered by all Cloudwatch events). Our Lambda functions follow the naming convention, adding a simple pattern matching rule to the ingestion pipeline automatically gives us filters on all these attributes. With the full-text search and temporal filters provided out of the box by Datadog, we can explore our logs to our heart’s content.
Correlation helps root causation
Even with all your logs in the same place and an easy way to sort and search them, it can still be a challenge to debug an issue, especially with a micro-service architecture where requests are passed from Lambda to Lambda. We solved this issue with correlation IDs, which are automatically inserted by AWS in the context of a new request and are passed along from service to service. Grabbing the correlation ID from the context and adding it to the logs makes it trivial to follow an interaction during its entire life cycle, even if it happens to go through several Lambda functions.

Managing secrets

Environment variables are a breeze to use with Lambda functions, and all serverless frameworks will allow you to configure and populate environment variables out of the box.
However, environment variables should not be used for everything, and especially not to hold sensitive information! They are usually handled in clear text, stored in configuration files and committed along with the code: there are a lot of ways for these values to leak, and you don’t want the world or even “just” everyone with read access to your Git repo to know the API keys for your payment provider…
AWS offers the SSM Parameter Store as a simple solution to hold key-value pairs securely. Values can be stored encrypted, with very fine-grained read and write access, making it ideal to manage sensitive information.
We use Parameter Store with a “namespace” strategy to manage variable scope: each variable name is prefixed either with <API name>\_<function name>, <API name>\_common or global depending on who can read its content (only a given function, all functions in the API, or everyone). This gives us tiered access rights without having to explicitly configure read rights for each variable.
Using Parameter Store rather than environment variables does have a performance cost, as the variable must be fetched and deciphered each time. To mitigate this, we use the ssm_cache Python library to cache values in memory, with a custom development to trigger cache invalidation as needed.
AWS has recently launched the Secrets Manager service, which looks like Parameter Store on steroids — we may move to this new service once we’ve had a chance to test it.
Service discovery

In the first part of this series, I mentioned that we build and deploy a new stack every time we make a change to an API. Each stack is given a unique name through the use of a commit tag and timestamp.
Only one stack is active at a time, but we may have several stacks of the same API deployed concurrently. In production, we will usually keep the previous version of each API in addition to the current one should we need to roll back. In staging, it’s common to have several versions around, as each pull request generates a new stack. This raises the question of how to keep track of the active stack.
The most common way to interact with a stack is through its public service endpoint, which, as described above, points to the active stack via a custom domain name: in this case, there’s no ambiguity in which stack is called. However, it’s also common to call Lambda functions directly. Lambdas can also be triggered by SNS notifications, or DynamoDB streams. In these cases how do we know which stack to use ?
Once again, SSM Parameter Store to the rescue! We store the active stack for each API in a global parameter, and update this parameter when we change the active stack. This effectively turns the active stack ID into a shared, centralized environment variable.
This information is used either by the calling Lambda function (to know which function to target), or by the called Lambda function (to determine if it’s active and therefore should react to SNS notifications and such).
More serverless goodness

Although the focus of this article is on how we build and host our APIs, this isn’t the only use case for which we’ve found serverless to be a good fit.
Our websites are hosted on S3 buckets + CloudFront. This set-up is a good fit for static websites, but also (with a little tweaking) for single page applications. In particular, we’ve built a customer portal on top of our subscription API, using vue.js for the client-side logic. This design pattern (a single page application backed by an API) works well when your website is basically a GUI to consume existing APIs, but can introduce needless complexity in other scenarios: for instance, when you don’t have an API to start with (and it wouldn’t make sense to build one), or when you don’t need a lot of client-side logic and interaction.
(Note also that although S3 + Cloudfront is a great way to quickly and cheaply host a website, you need to jump through some hoops to have more control over how your content is served — e.g. you have to set up a Lambda@Edge function to add security headers)
So when we needed a simple back-office website to review complex claims, instead of going the SPA + API route we built a simple Flask app that we bundled in a Lambda function. With a few tweaks to our CI scripts, we were able to include this new application in our existing API deployment process, and voilà, a simple serverless back-office in a few days of work.
On the back-end, we’ve tested the new WebSocket API feature from API Gateway, which we use to communicate with our claim-processing bot. It’s still early days for this feature (for instance, there was no initial CloudFormation support for it) but the ability to push notifications from the server to the client really simplifies workflows with long-running server processing, which don’t lend themselves well to traditional HTTP requests.
Until next time…
Well, this (temporarily) concludes the feedback from our journey into serverless. Our architecture is still very much a work in progress and we expect our tools and processes to keep evolving; for instance, we’ve started using Terraform for new services, and it will probably replace our CloudFormation / Ansible scripts at some point. We will also experiment with new serverless use cases as we develop new services and grow our IT plaform.
So stay tuned for further updates !